

Перевод статьи Дэвида Андерсона, размещённой на djaa.com.
Оригинал можно прочитать здесь.
Читайте 1-ю часть этой серии статей по ссылке.
Взгляд со стороны: недавно я посетил пятидневный курс «Реальные риски» с Нассимом Талебом. Говоря о науке в целом и управлении рисками в частности, Талеб сказал, что не существует принципа «давайте предположим». Я намерен включить это заявление во все записи в блогах, связанные с управлением рисками, прогнозированием, планированием и так далее. Каждый раз, когда вы видите, что мне приходится использовать фразу «давайте предположим», чтобы защитить или отстаивать существующий метод, который я считаю ошибочным, мы переходим в область фантастики. Не существует принципа «давайте предположим».
Использование стоимости задержки для определения приоритетов или выстраивания последовательности работ становится все более популярным в сообществе Agile. Есть несколько авторов, которые популяризуют несколько схожие количественные, математические подходы к ранжированию запросов для определения приоритетов или упорядочивания серии конкурирующих запросов. Дональд Рейнертсен популяризует использование техники теории очередей, известной как WSJF (Weighted Shortest Job First — взвешенная продолжительность самой короткой задачи), а Джошуа Арнольд пропагандирует более простую, по его мнению, производную CD3 (Cost of Delay Divided By Duration — стоимость задержки, поделенная на продолжительность). Некоторые другие авторы используют производные от этих двух идей и часто, что сбивает с толку, называют их одинаково, даже несмотря на то, что они изменили параметры в уравнениях. И WSJF, и CD3 используют «продолжительность» в качестве знаменателя, и я показал то, что мы знаем о продолжительности, для различных аспектов запросов на интеллектуальную работу. В первой части рассматривались индивидуальные активности, а во второй — запрос клиента, который проходит через серию активностей по добавлению информации или знаний в рабочий процесс предоставления услуг.
Канбан-сообщество с момента появления в 2007 году измеряет, сообщает, изучает и действует на основании информации о продолжительности. У нас были данные об индивидуальных активностях и продолжительности рабочих процессов в первой Канбан-системе в Microsoft в 2004 году. В Канбан-сообществе продолжительностью обычно называют время выполнения заказа. Оно недвусмысленно определяется как время от взятия обязательства принять, выполнить и поставить запрос клиента, и до момента фактического получения этим клиентом. Имея опыт и данные за десятилетие, мы многое узнали о продолжительности.
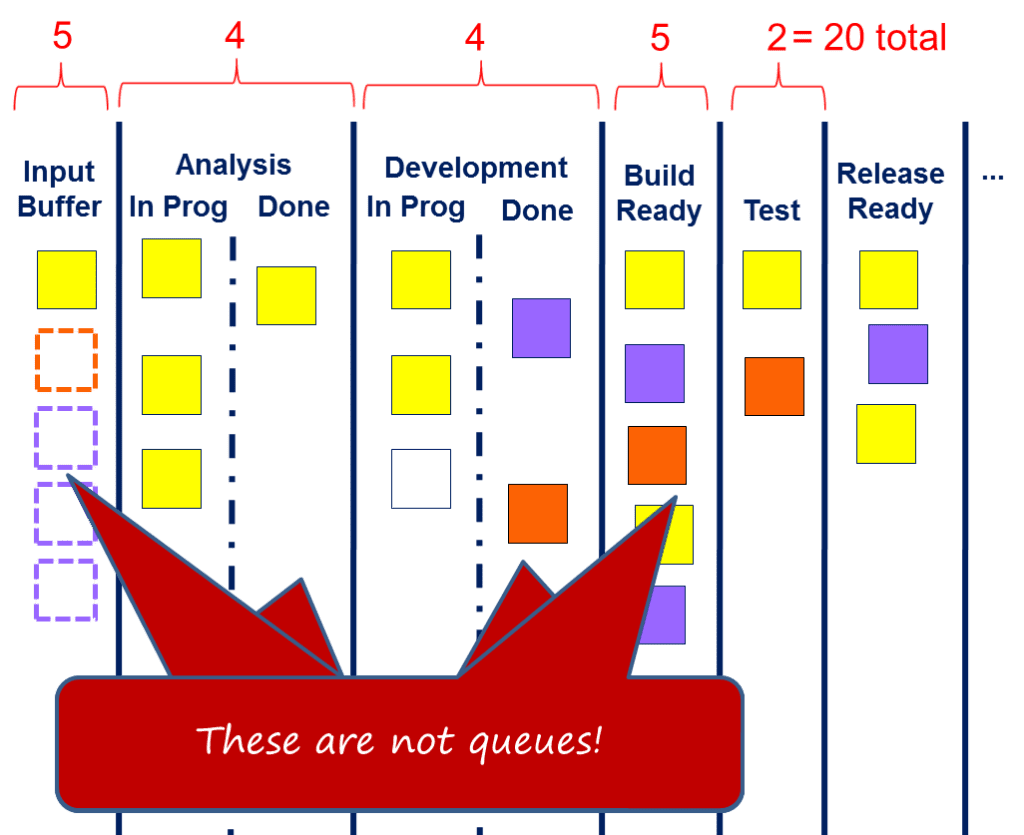
На Рис. 1 показаны типичная доска и Канбан-система. На доске есть несколько буферов и состояний ожидания. Важно понимать, что буферы или состояния ожидания не являются очередями и обычно не имеют определенной дисциплины очередей. Точнее, эти буферы и состояния ожидания больше похожи на то, что инженеры-промышленники называют «супермаркетами», я считаю более полезным думать о них как о «конкурсах красоты». Элемент будет выбран из состояния ожидания или буфера, если есть доступные рабочие с правильными навыками и если профиль риска элемента таков, что это лучший выбор с учетом набора доступных вариантов. Иногда вариант может быть только один. В других случаях этот единственный вариант зависнет в ожидании, потому что у свободных рабочих нет необходимой квалификации. Ключевой урок состоит в том, чтобы признать, что время ожидания или задержка в буфере или состоянии ожидания не могут быть определены заранее, они полностью произвольные и, следовательно, недетерминированные по своей природе.
Следующее, что нужно понять, — насколько большая задержка на самом деле типична для профессиональных услуг, интеллектуальной работы, рабочего процесса. Отношение общей продолжительности ко времени, потраченному на ожидание, называется эффективностью потока. На Рис. 2 показано, как рассчитывается эффективность потока. В лучших тематических исследованиях, о которых сообщалось в Канбан-сообществе, эффективность потока достигает более 40%. В самой первой Канбан-системе в 2004 году она начиналась с 8%. Оказывается, 8% — это высокое начальное значение, были сообщения и об 1−2%. Обычно мы ожидаем, что эффективность потока будет в диапазоне 1−25%, причем, в большинстве случаев, это будет нижняя граница вышеуказанного диапазона. Поэтому есть важное следствие: для продолжительности рабочего элемента от 75 до 99% времени составляет время ожидания, а ожидание полностью недетерминировано по своей природе.
Остальные 1−25% рассматриваются в первой статье этой серии «Что мы знаем о продолжительности: индивидуальные активности». Вывод этой предыдущей статьи состоит в том, что продолжительность отдельной задачи может варьироваться в пределах 200 раз от минимума до максимума, она не детерминирована по своей природе. Теперь мы знаем, что эта недетерминированная продолжительность задачи составляет от одной сотой до одной четверти общей продолжительности. Таким образом, у нас есть полностью недетерминированное время задержки, которое составляет 75−99% от общей продолжительности, и сумма длительностей задач, которые могут меняться по масштабу на 2 порядка, и составляют остаток. Давайте предположим, что мы считаем, что можем определять размеры элементов и что их размер и сложность действительно коррелируют с продолжительностью отдельной задачи, тогда у нас все еще есть проблема с недетерминированностью буферов и состояний ожидания, которые определяют фактическую продолжительность рабочего процесса. Даже если бы мы могли точно сказать «эта пользовательская история займет 4 дня», вполне вероятно, что общая продолжительность составит от 16 до 400 дней. Представьте, что мы сравниваем этот элемент с другим, выполнение которого, по нашему мнению, займет всего 2 дня. Наш детерминистский анализ, без сомнения, предполагает, что задание 2 будет выполнено раньше задания 1. Однако реальность недетеминированных состояний буфера и ожидания означает, что вероятность того, что второй элемент (выполнение которого мы оценили как половину времени по сравнению с первым) на самом деле будет выполняться дольше, близка к 50%. Помимо того, что вероятность более продолжительного выполнения близка к 50%, существует вероятность того, что выполнение может занять в пределах 100 раз больше времени.
В управлении рисками 50-процентная вероятность того, что потребуется больше времени, известна как «вероятность x», в то время как фактическое большее количество времени известно как «функция от x или f (x)». В управлении рисками нам нужно больше беспокоиться о f (x) — или воздействии — чем о вероятности. Если бы мы использовали наши значения за 4 дня в сравнении с 2 днями в уравнении приоритизации для принятия решений о выстраивании последовательности, существует почти 50% вероятность того, что мы примем неправильное решение с точки зрения выстраивания последовательности, и влияние неправильного решения может быть существенным. Учитывая, что эти два элемента существуют не в вакууме, сложность проблемы резко возрастает, если мы рассмотрим значительное количество других альтернатив, с которыми мы будем их сравнивать. Достаточно всего лишь нескольких элементов сравнения, и мы достигнем точки, в которой вероятность правильного выстраивания последовательности из них на основе продолжительности стремительно приближается к нулю. И, конечно же, весь этот анализ включал в себя «давайте предположим», что мы действительно можем правильно определить продолжительность отдельной задачи. Но это предположение является ложным, как мы знаем из первой части этой серии статей.
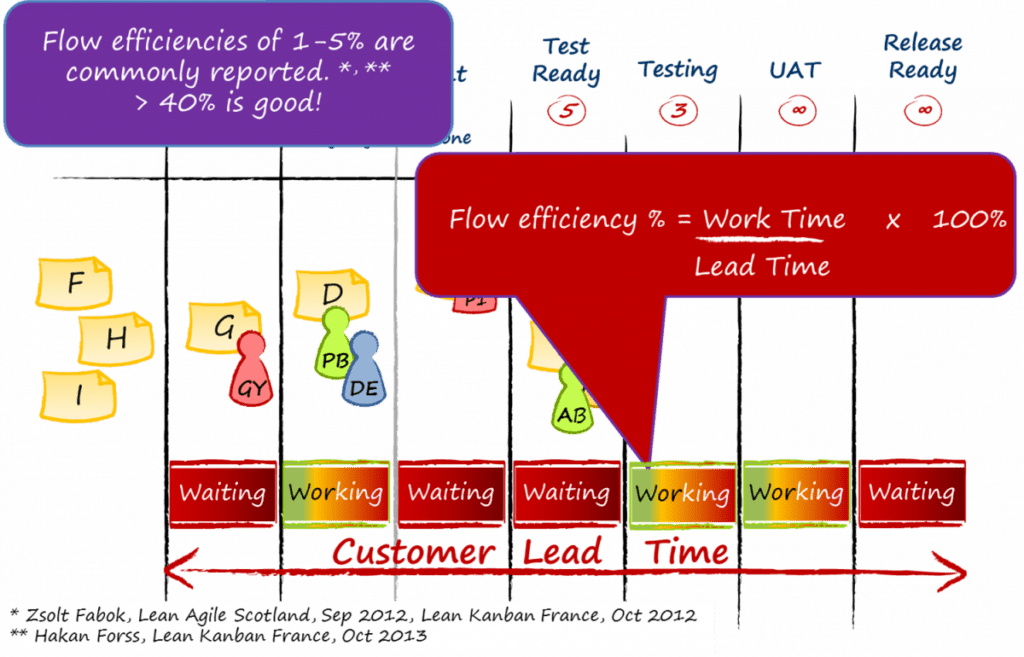
Рис. 3, 4 и 5 были предоставлены Рамешем Патилом, техническим директором Digite, и взяты из аналитики данных реальной разработки функционала программного обеспечения в продукте SwiftKanban.
Хочешь разобраться, что тебе даст Канбан?
Выбери, что ближе твоему запросу — и получи 🎁 подарок
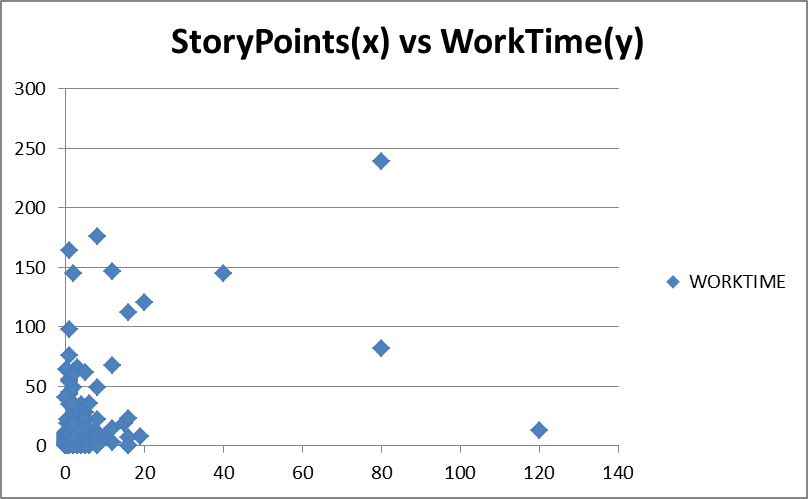
На Рис. 3 показано количество баллов за историю в эпике по сравнению с фактическим записанным рабочим временем для таких действий, как разработка. Если бы существовала корреляция между размером эпика, состоящей из агрегированного набора пользовательских историй индивидуального размера, мы бы увидели кластер точек в виде примерно линейной диагональной линии от начала координат к правому верхнему углу графика. Мы этого не видим, и разброс точек говорит о том, что корреляции нет.
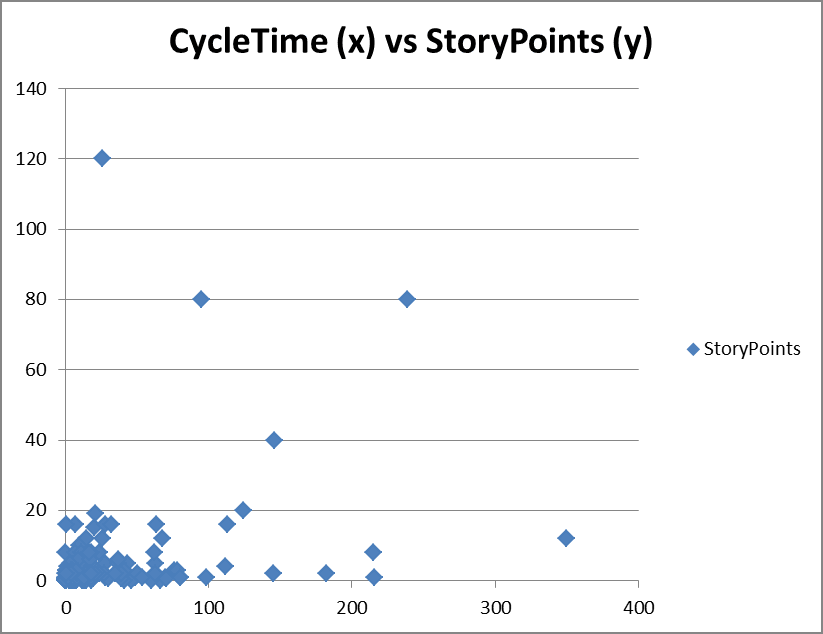
На Рис. 4 термин «время цикла» фактически отражает время выполнения заказа или продолжительность от момента принятия до готовности к предоставлению. В этом примере мы наносим баллы за историю для эпика, агрегированных из набора историй индивидуального размера, в сравнении с фактической продолжительностью, необходимой для завершения заказа. Если бы была корреляция, мы бы увидели кластеризацию точек на примерно прямой линии от исходной точки до правого верхнего угла графика. Мы этого не видим и, как следствие, можем сделать вывод, что количество баллов за историю не коррелирует с продолжительностью и не может использоваться для расчета стоимости задержки с использованием уравнений WSJF или CD3.
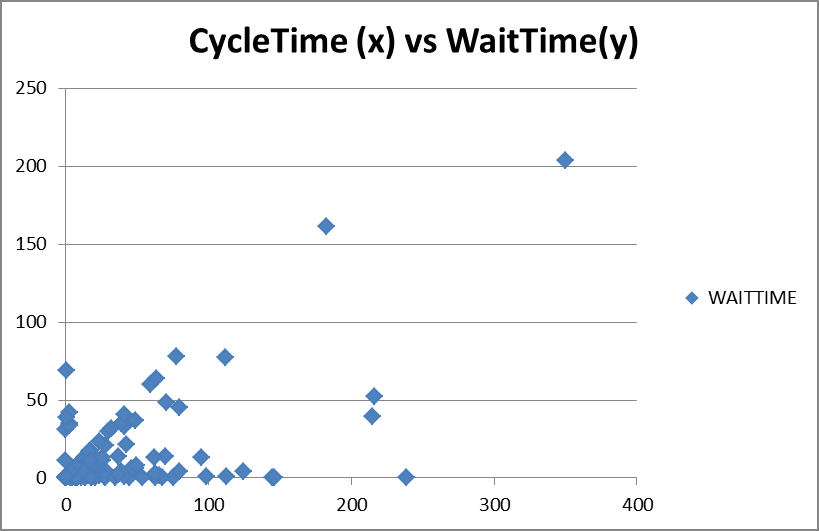
На Рис. 5 показан график общей продолжительности или времени выполнения заказа в зависимости от времени ожидания заявки. На этом графике мы видим некоторую корреляцию. Это строго определенный линейный график точек, поднимающихся по диагонали от начала координат к верхнему правому углу. Мы также видим несколько точек на оси X. У них высокая эффективность потока. Это типично для элементов обслуживания «ускоренного» класса. Промежуточные позиции в нижней правой половине графика под диагональю предполагают элементы с более высокой эффективностью потока, возможно, получающие более высокий класс обслуживания, это могут быть элементы с какой-то фиксированной датой предоставления. Но с учетом характера разработки продукта, они, скорее, являются дефектами при более высоком классе обслуживания, направленном на устранение блокировками основной разработки.
В верхнем левом углу диаграммы почти нет точек, потому что мы не ожидаем увидеть какие-либо точки, где общая продолжительность была меньшей, чем время ожидания. Несколько точек, сгруппированных вокруг оси Y, могут быть шумом в наборе данных или потребовать дальнейшего исследования.
Из Рис. 5 видно, что самый лучший способ повлиять на продолжительность — это, по сути, использование классов обслуживания. Предоставляя элементу более высокий класс обслуживания, мы фактически делаем его более «красивым», чем другие заявки. Ему отдается предпочтение при принятии решений о выборе. Как следствие, он тратит намного меньше времени на ожидание, а время выполнения заказа резко сокращается. Для действительно ускоренной заявки продолжительность будет выглядеть как продолжительность отдельной задачи, как показано в первой части этой серии статей, или как сумма продолжительностей нескольких отдельных задач.
Время выполнения (или продолжительность) распределено по закону Вейбулла
На Рис. 6 показаны сводные кривые распределения для сроков выполнения заказа. Они соответствуют распределению Вейбулла с различными значениями параметра формы.
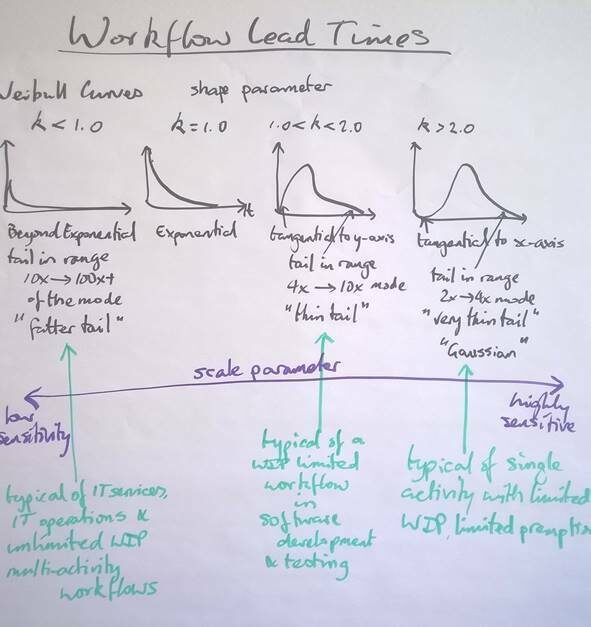
Как описано в первой части этой серии, индивидуальные действия, когда они не были упреждены, будут иметь форму, близкую к гауссовой, с кривой Вейбулла с параметром формы каппа, k, лежащим в диапазоне 2,0 < k < 4,0. Однако, учитывая, что упреждение все же происходит и возникает некоторая задержка, а также учитывая, что конкретный элемент определенного типа может по-прежнему иметь размер и сложность, которые варьируются на два порядка, вполне вероятно, что мы увидим продолжительность задач с кривой распределения, имеющей параметр формы в диапазоне 1,5 < k < 2,0. В некоторых доступных нам наборах данных, например данных о деятельности по разработке из первой Канбан-системы в Microsoft в 2004 году, параметр формы чуть больше, чем k = 2,0, но для тестирования он ближе к k = 1,7. Это говорит о том, что тестировщиков опережали или задерживали чаще, чем разработчиков.
Для рабочих процессов, в которых мы используем Канбан, ограничивая незавершенную работу, упреждение в действиях, доступные варианты в состояниях ожидания и буферах и, следовательно, повышая эффективность потока до диапазона 25−40%, мы обычно видим кривые распределения времени выполнения заказа с параметром формы 1,0 < k < 2,0 и обычно в диапазоне 1,3 < k < 1,6.
Если мы движемся к пре-канбану, неограниченному количеству незавершенных работ и отсутствию внимания к устранению задержки, отсутствию предотвращения или смягчения проблем с блокировками, мы постепенно наблюдаем, что параметр формы уменьшается до значения k = 1,0 (экспоненциальная функция), а затем и ниже его. Мы называем это «левым формированием» или «правым перекосом» распределения, поскольку хвост все длиннее и длиннее тянется к правой стороне. Более длинный хвост означает, что у нас все меньше и меньше предсказуемости и все больше и больше влияние задержки. Возможно, существует лишь небольшой процент элементов, которые откладываются на более длительные периоды, малая вероятность x, но продолжительность задержки, влияние f (x) значительно. Именно здесь возникают проблемы, особенно в организациях с более низкой зрелостью, которые паникуют при стрессе. Значения параметра формы k ниже 1,0 соответствуют ситуациям с высоким риском и большой вероятностью нежелательных результатов. Мы связали распределения с длинным и толстым хвостом с k < 1,0 с ИТ-работами, ИТ-услугами и разработкой программного обеспечения с очень низким уровнем зрелости. Опубликованы наборы данных в диапазоне k ~ 0,75.
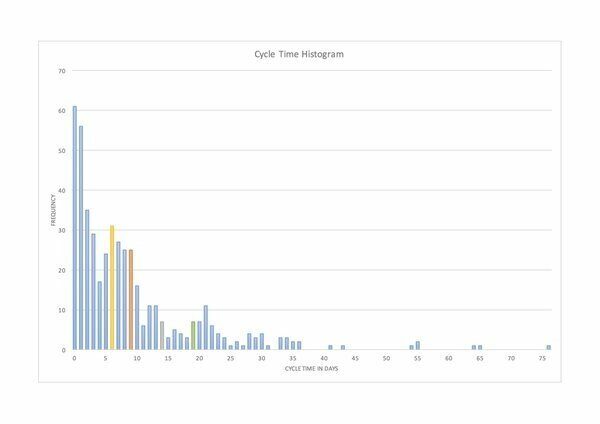
Андреас Бартель из Гамбурга опубликовал эти данные о времени (продолжительности) поставки ИТ-услуг в Twitter в начале марта. Мода в этих данных составляет менее 1 дня, медиана — 6 дней, среднее арифметическое — 9 дней, а хвостовая часть в наборе данных составляет 77 дней, или примерно в 100 раз больше, чем мода. Для этого набора данных параметр формы Вейбулла принимает значение k ~ 0,8.
Моделирование наборов данных о времени выполнения
В сообществе развиваются две школы. Одна школа, возглавляемая такими светилами, как Трой Магеннис, Ларри Максерон и Рамеш Патил, считает, что нет смысла пытаться построить кривые распределения «наилучшего соответствия». Вместо этого они предпочитают стиль статистического моделирования и симуляции, известный как «бутстрэппинг», где они используют только точки из набора исторических данных и игнорируют пробелы. Другая школа считает, что для истинного моделирования Монте-Карло нужны параметрические модели. По сути, аргумент — это ошибка модели против ошибки прогноза. Учитывая, что любой из подходов дает прогнозы, которые намного превосходят другие существующие методы для гибкой разработки программного обеспечения, это, в некотором роде, эзотерическая точка, она в значительной степени находится на «переднем крае Канбанленда» с точки зрения экспериментирования и разрешающей способности.
На Рис. 8 показано распределение времени выполнения для разработки программного обеспечения и тестирования функциональности архитектуры среднего уровня телекоммуникационного узла. Это распределение было зафиксировано у одного из моих клиентов и извлечено из программы отслеживания Jira летом 2014 года.
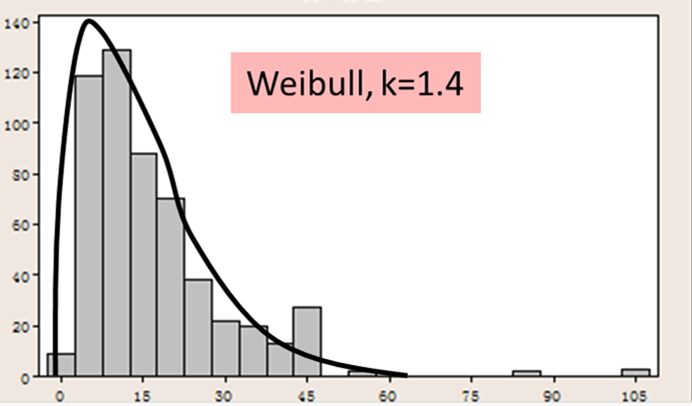
Набор данных достаточно хорошо соответствует распределению Вейбулла с параметром формы k ~ 1,4 и параметром масштаба 61. Однако есть и некоторые отдаленные точки данных. Хвост длиннее и толще, чем можно было бы смоделировать по кривой Вейбулла. Это типично для многих реальных наборов данных.
На Рис. 9 показана модель, аналогичная реальным данным на Рис. 8. Ее можно смоделировать с помощью двух кривых Вейбулла: одной с тонким хвостом с формой k > 1,0, а другой с более толстым хвостом с формой k < 1,0. Имея лишь две кривые, мы получаем параметрическую модель, которая довольно точно моделирует реальный набор данных. Эту агрегированную параметрическую модель или кривую распределения можно использовать в моделировании Монте-Карло для прогнозирования результата для большего набора элементов, проходящих через один и тот же рабочий процесс обслуживания, или для установления ожидаемых уровней обслуживания или соглашений о предоставлении услуг.
Выводы
Что мы знаем о продолжительности:
- Продолжительность (или время выполнения заказа) соответствует кривым распределения Вейбулла, но с более длинными и толстыми хвостами. Обычно для адекватного моделирования реального набора данных необходимо сопоставить две кривые.
- Кривая распределения времени упреждения обычно демонстрирует разброс вариаций между модой и хвостом в 4−200 раз. Разброс отклонения от наименьшего до наибольшего значения может находиться в диапазоне от 50 до 200 раз.
- Сроки выполнения полностью недетерминированы
- Наибольшее влияние на время выполнения заказа можно достичь за счет сокращения времени ожидания.
- Лучший способ положительно повлиять (сократить) время выполнения заказа — это использовать классы обслуживания, которые сокращают время, затрачиваемое на состояния ожидания и буферы.
- Ограничение количества незавершенных работ с помощью Канбан-системы имеет драматический положительный эффект (сокращение) для времени выполнения заказа, поскольку сокращает выбор состояний ожидания и буферов и увеличивает вероятность того, что элемент будет выбран для следующего действия.
- Параметры формы кривой Вейбулла для сроков выполнения заказа в рабочих процессах предоставления услуг варьируются в диапазоне 0,5 < k < 2,5 в наблюдаемых наборах данных из реального мира.
- Различия в размере или сложности для элементов одного типа не коррелируют со временем выполнения заказа (продолжительностью).
- Класс обслуживания для элементов одного типа действительно коррелирует со временем выполнения заказа, так как эффективность потока значительно повышается.
- Ускоренный класс элементов обслуживания для элементов того же типа будет демонстрировать распределение времени выполнения заказа с параметром формы Вейбулла k в диапазоне около 2,0.
- Эффективность потока редко превышает 40%. Обычно эффективность потока без использования Канбан-системы и улучшения процесса, направленного на уменьшение задержки и устранение проблем с блокировкой, обычно составляет менее 10%, а иногда всего 1%. Как следствие, размер или сложность элемента очень мало влияют на его продолжительность.
- Состояния ожидания и буферы в профессиональных сервисах, рабочие процессы со знаниями не являются очередями и редко имеют какую-либо дисциплину очереди, если это явно не указано в определении класса обслуживания. Как следствие, время ожидания полностью недетерминировано.
- Поскольку эффективность потока низкая, а время ожидания полностью недетерминировано, для элементов данного типа невозможно определить их продолжительность более точно, чем границы кривой распределения времени выполнения заказа.
В качестве общего вывода, если мы имеем дело с элементами одного и того же типа, например, пользовательскими историями по сравнению с другими пользовательскими историями, с явным намерением использования продолжительности для помощи в выстраивании последовательности работ с использованием уравнения стоимости задержки, такого как WSJF, мы не можем заранее определить или отличить продолжительность одной пользовательской истории от другой. То же самое верно и для рабочих элементов разного масштаба, таких как эпики, совокупный набор связанных пользовательских историй. Мы не можем определить продолжительность одного эпика по сравнению с другой.
В масштабе проекта — как минимум на 2 порядка большего, чем отдельная пользовательская история — мы можем смоделировать продолжительность проекта, учитывая известный определенный, детерминированный объем пользовательских историй, используя моделирование Монте-Карло. Это будет темой следующей публикации из серии про стоимость задержки.